
|
今日のコンピュータは日本の文字をあつかえるようになっている。しかし時々文字化けが発生して内容が読めない場合もある。ここではその舞台裏を見ることにする。
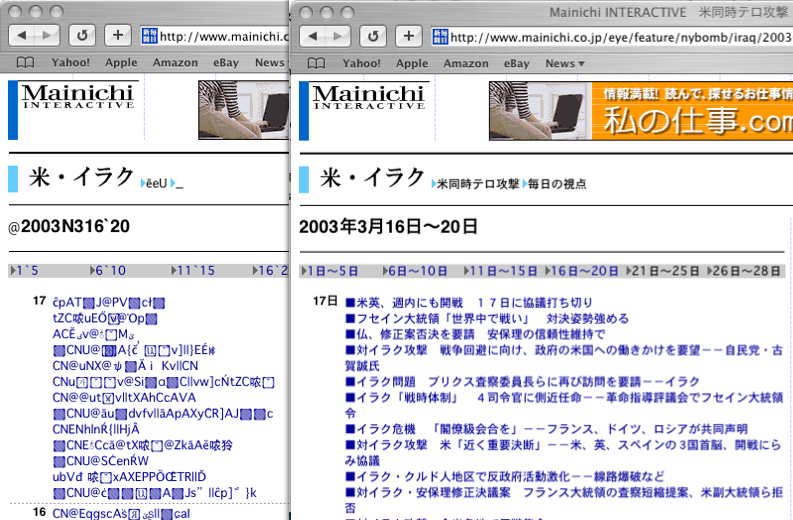
左は文字化け、右が正しい
次の部分は画像として送られている

画像情報は解釈のルールが確立しているので正しく読みとれる
数字の部分も概して正しく読みとれていることに注意する。英字や数字など ASCII 文字は異なる解釈の余地はないので、混乱はないのである。
問題は日本語の文字である。
現在、インターネットで使用されている日本語文字のコードの解釈には4つある
| エンコーディング | システム | メモ |
|---|---|---|
| JIS 漢字コード | 汎用機で発展 | 正確には iso-2022-jp |
| シフト JIS | パソコンで発展 | あるいは MS-Kanji コード |
| 日本語 EUC | UNIX で発展 | ujis とも言う |
| UTF-8 | 国際標準 | ユニコードをネットワークに適合するように変形 |
同じ文字を表すのに、これらの間で使用するコードが異なる。例えば、
| 文字 | JIS | SHIFT JIS | EUC | UTF-8 |
|---|---|---|---|---|
| あ | 2422 | 82A0 | A4A2 | E38182 |
| 愛 | 3026 | 88A4 | B0A6 | E6849B |
| 右 | 3126 | 8940 | B1A6 | E58FB3 |
文字コードの違い。16進数でコードが表されている
情報の送り手と受け手が異なるコードの解釈をするために問題が発生する。たいていの Web のブラウザは、文字が化けた場合の対策として、幾つかの可能性を試せるようになっている。例えば、
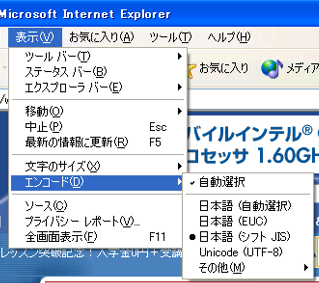
JIS は特徴があるので受ける側が判別しやすい。しかし残りはよく似ているので、解釈を間違えることがある。
そのとおりだ。そして実際にその仕組みは存在する。しかしそれを使用しない Web のサイトがあり、その場合には文字化けが発生することがある。
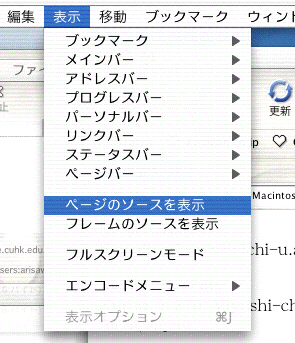
Opera(この講義で使用しているブラウザ)のメニュー
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html><head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>漢字コード</title>
コード化の方法。日本語の漢字を扱える文字のエンコーディングには以下の5つが存在する。
ISO(International Standardization Organization、国際標準化機構 http://www.iso.org )
いずれも漢字だけではなく以下の文字を扱うことができる。
コメント
例: 愛
| エンコーディング | コード(16進) | コード(2進) |
|---|---|---|
| JIS | 30 26 | 00110000 00100110 |
| EUC | B0 A6 | 10110000 10100110 |